Hyperlinks are the linking blocks of all web applications. You can link one webpage to the other by using hyperlinks. Sometimes when a website contains hundreds of links it is hard to locate that which links are working and which are not. In this article I will demonstrate that how you can find out that if the hyperlink of a webpage is exists or not
Introduction:
Hyperlinks are the linking blocks of all web applications. You can link one webpage to the other by using hyperlinks. Sometimes when a website contains hundreds of links it is hard to locate that which links are working and which are not. In this article I will demonstrate that how you can find out that if the hyperlink of a webpage is exists or not.
Getting all the urls of the Page:
Our first task is to get all the urls (hyperlinks) on the page. Once, we have all the hyperlinks contained in a webpage we can iterate through the links and find out which of them exists. Check out the code below which demonstrates that how you can extract the HTML of a page.
List<BadUrl> badUrlList = new List<BadUrl>();
WebRequest req = WebRequest.Create("http://
localhost:2640/BadUrls/UrlList.aspx");
HttpWebResponse res = (HttpWebResponse)req.GetResponse();
Stream stream = res.GetResponseStream();
ArrayList badUrls = new ArrayList();
StreamReader reader = new StreamReader(stream);
string html = reader.ReadToEnd();
The WebRequest class contains the Create method which makes the request to provided url. The GetResponse method is used to get the response from the web server. After getting the response we read the ResponseStream in the string format and save the output in a string variable called "html".
The string variable "html" will contain all the HTML tags of the requested page. At this point we need to extract the links out of the HTML. For this we will need a regular expression. Check out the code below which uses a regular expression to extract all the links out of the HTML of the page.
// Get the links
string pattern = @"((http|ftp|https):\/\/w{3}[\d]*.|
(http|ftp|https):\/\/|w{3}[\d]*.)([\w\d\._\-#\(\)\[\]\\,;:]
+@[\w\d\._\-#\(\)\[\]\\,;:])?([a-z0-9]+.)*[a-z\-0-9]+.([a-z]
{2,3})?[a-z]{2,6}(:[0-9]+)?(\/[\/a-z0-9\._\-,]+)*[a-z0-9\-_\
.\s\%]+(\?[a-z0-9=%&\.\-,#]+)?";
Regex r = new Regex(pattern);
MatchCollection mC = r.Matches(html);
The MatchCollection variable "mC" will contain all the matches of the regular expression. In this case mC will be filled with all the hyperlinks. Now, we can check the hyperlinks one by one and find out that if it exists or not.
Making Sure that the Hyperlink Exists:
First, I must admit that the method that I am going to use is not the best method. Second, the method when executed takes awful amount of time and can result in a timeout. Also, this method will not work if your ISP is redirecting you to a custom page when the page not found exception is thrown.
private bool DoesUrlExists(string url)
{
bool urlExists = false;
try
{
WebRequest req = WebRequest.Create(url);
HttpWebResponse response = (HttpWebResponse)req.GetResponse();
urlExists = true;
}
catch (System.Net.WebException ex)
{
}
return urlExists;
}
As, you can see from the code above that the whole logic is based on the exceptions. If the exception is thrown then it will be assumed that the url does not exists else the url exists.
I made a simple test file to make sure that the application works as expected. Take a look at the file below which have some real urls and some dummy urls.
UrlList.aspx:
<div>
<a href="http://localhost:1852/LookIntoDoPostBack/UrlList.aspx">My Url </a>
<a href="http://localhost:1122/LookIntoDoPostBack/UrlList.aspx">My Url </a>
<a href="http://localhost:1672/LookIntoDoPostBack/UrlList.aspx">My Url </a>
<a href="http://www.jhasd.aspx">My Url </a>
<a href="http://www.bhbbbagsdns.aspx">My Url </a>
</div>
I have also made the interface a little better so that the user will have a better idea of what is happening.
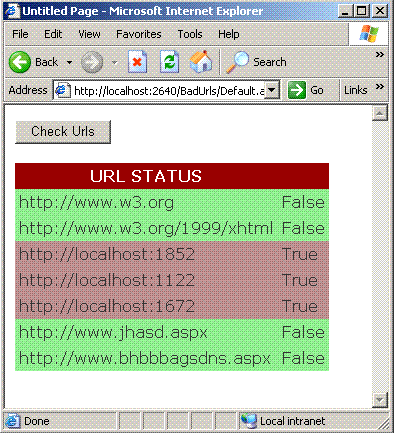

The urls which are highlighted in dark pink are the urls that does not exists and the ones in the light green are the ones which exists. As, you can see that the application shows that the urls www.jhasd.aspx and www.bhbbagsdns.aspx exists but in reality they do not exist. The reason the dummy links are showing as exist is that the ISP is redirecting the page not found requests to a custom page which exists. My suggestion is that when you are running this application make sure that the page not found requests are not redirected to the custom ISP page.
I have included the download samples files which can be downloaded at the end of this article.
I hope you liked the article, happy coding!